获取文本
例如我想获取本博客的这段文字
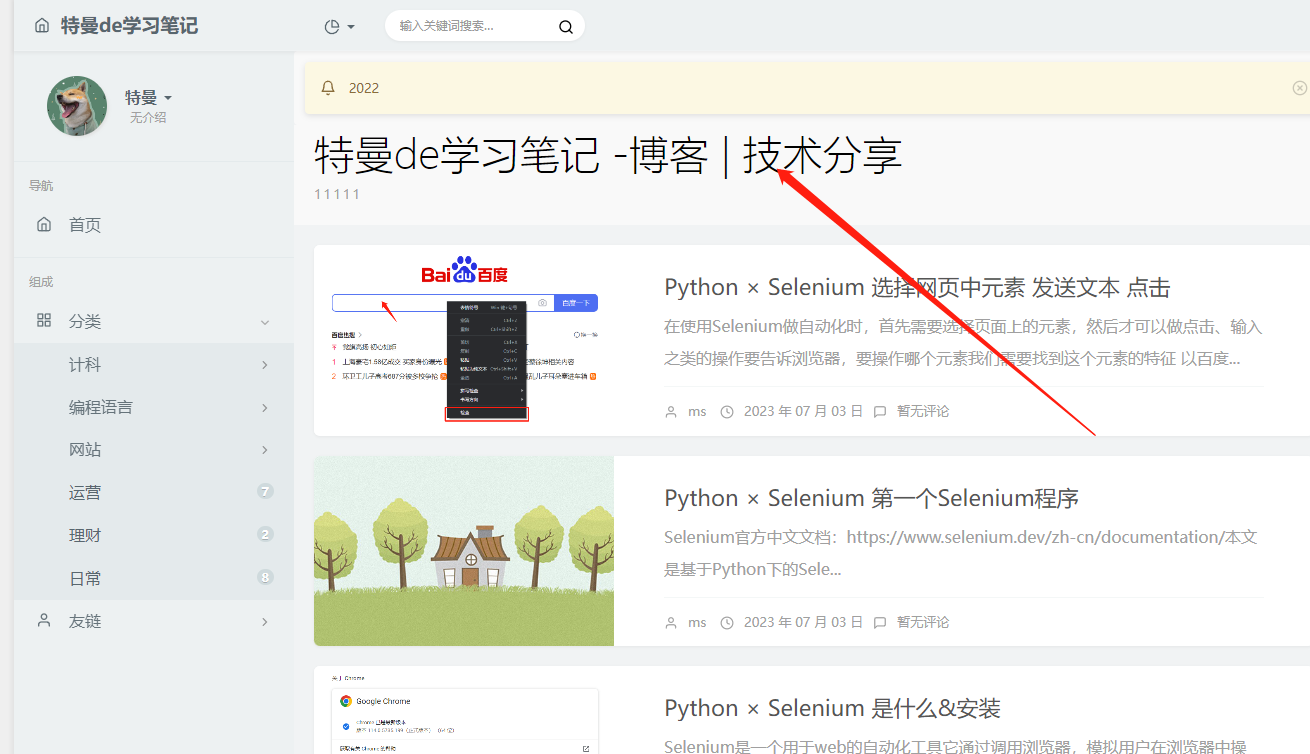
首先第一步,还是定位这个元素

注意之前提到的 空格用.来代替
element = wd.find_element(By.CLASS_NAME,'m-n.font-thin.text-black.l-h')使用element.text就可以获取到了
这里print一下
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
wd = webdriver.Chrome(service = Service('chromedriver.exe'))
wd.get('https://www.yuofyou.cn')
element = wd.find_element(By.CLASS_NAME,'m-n.font-thin.text-black.l-h')
print(element.text)
input()成功获取到
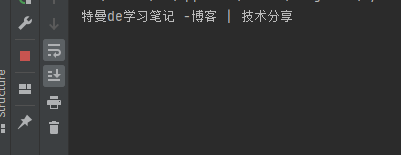
获取元素属性值
如果我们想获取到第一个文章的链接
观察第一个文章对应的代码

链接出现在了一个class名为m-t-none text-ellipsis index-post-title text-title里面的a标签的href属性
首先我们还是定位这个最外层的元素(注意这里因为我们想获取的是第一个文章 所以就直接使用element即可,无需使用elements)
element = wd.find_element(By.CLASS_NAME,'m-t-none.text-ellipsis.index-post-title.text-title')如果直接获取href属性是获取不到的。因为这个class本身是没有href属性的。我们需要再定位到它下层的a标签
这里使用By里面的TAG_NAME方法,在 Selenium 中,通过 By.TAG_NAME 可以定位具有指定标签名称的元素。
element = element.find_element(By.TAG_NAME, 'a')然后使用获取元素属性的get_attribute
href = element.get_attribute('href')完整代码
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
wd = webdriver.Chrome(service = Service('chromedriver.exe'))
wd.get('https://www.yuofyou.cn')
element = wd.find_element(By.CLASS_NAME,'m-t-none.text-ellipsis.index-post-title.text-title')
element = element.find_element(By.TAG_NAME, 'a')
href = element.get_attribute('href')
print(href)
input()获取整个元素的HTML
在程序编写的时候有些时候需要debug。
可以获取一下整个页面的HTML 或者某个元素的HTML以此来查错
要获取整个元素对应的HTML文本内容,可以使用 element.get_attribute('outerHTML')
如果只是想获取某个元素 内部 的HTML文本内容,可以使用 element.get_attribute('innerHTML')