关系数据库基于关系模型,使用一系列表来表达数据以及这些数据之间的联系。
关系数据库也包括DML和DDL
在商用数据处理应用中,关系模型已经成为当今主要的数据模型
表
每个表有多个列,每个列有唯一的名字。
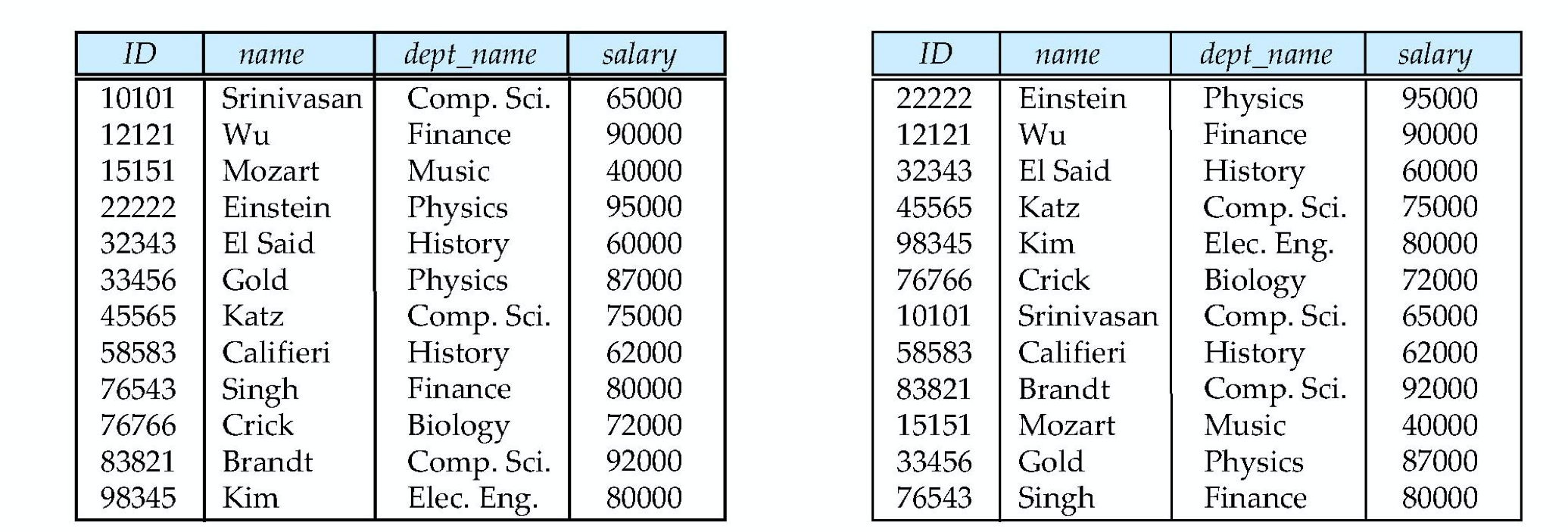
上图是两个表 用于表示教师id、名字、科目、年薪
关系模型是基于记录的模型的一个实例。每个表包含一种特定类型的记录。每种记录类型定义固定数目的字段或属性。表的列对应记录类型的属性。
不难看出,表可以存储在文件中,例如,一个特殊的字符(比如逗号)可以用来分割记录的不同属性。对于数据库的开发者和用户,关系模型屏蔽列这些低层实现细节。
数据操纵语言
SQL查询语言是非过程化的。它以几个表作为输入(也可能只有一个),总是仅返回一个表。下面是一个SQL查询例子,它找出历史系所有教员的名字
select instructor.name
from instructor
where instructor.dept_name = 'History';这个查询指定了从instructore表中要取回的是dept_name为History的那些行。并且这些行的name属性要显示出来
查询也可以涉及来自不止一个表的信息。
例如,这是从两个表(instructor和department)中找出salary值超过95000的所有人的id和名字
select instructor.id,department.dept_name
from instructor,department
where instructor.dept_name = department.dept_name and
department.salary>95000数据定义语言
SQL提供了一个丰富的DDL语言。通过它,我们可以定义表、完整性约束、断言等等
例如,下面的SQL DDL语句定义了department表
create table department
(dept_name char(20),
building char(15),
budget numeric(12,2));上面的DDL语句执行的结果就是创建了department表,该表有三个列
关系数据库的结构
关系数据库由表的集合构成,每个表有唯一的名字。例如
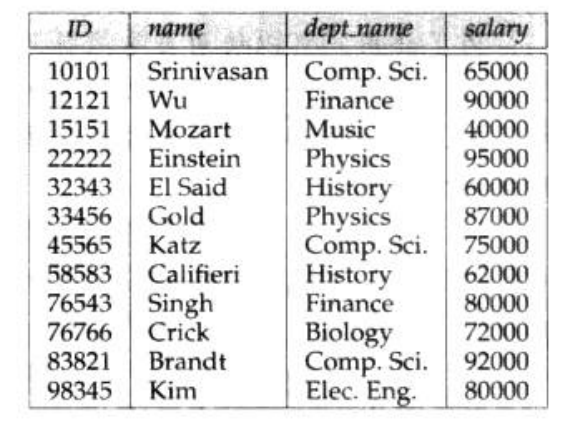
它有四个列首:ID、name、dept_name、salary
它的每一行都记录了一个教师的信息
再来看一个表:
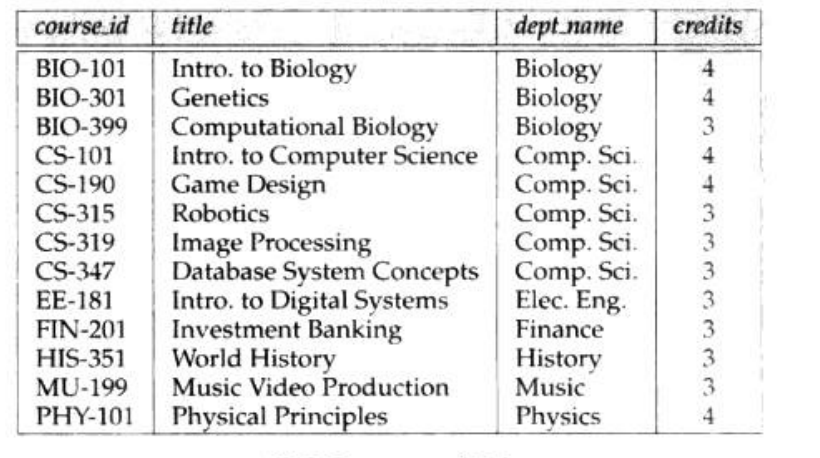
这个表存储了关于课程的信息
一般来说,表中的一行代表了一组值之间的一种联系。由于一个表就是这种联系的一个集合,表这个概念和数学上的关系这个概念是密切相关的,这也正是关系数据模型名称的由来。
在数学术语中,元组tuple只是一组值的序列(或列表)
在n个值之间的一种联系可以在数学上用关于这些值的一个n元组(n-tuple)来表示。换言之,n元组就是一个有n个值的元组,它对应于表中的一行
在关系模型的术语中
关系(relation)用来指代 表
元组(tuple)用来指代 行
属性(attribute)指代 表中的列
再回来看这个表:
这个实例有12个元组,对应于12个教师
由于关系是元组集合,所以元组在关系中出现的顺序是无关紧要的,如下图这样无序的排列都是可以的。
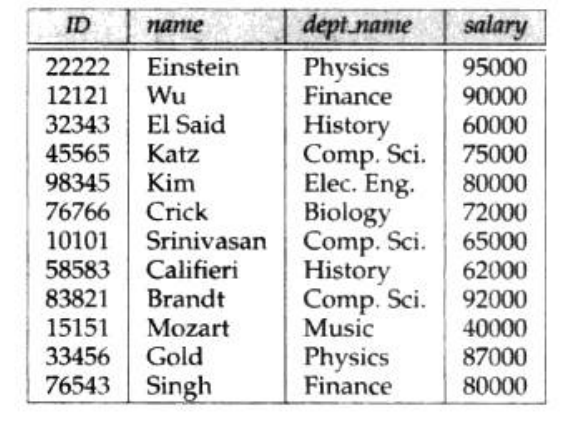
上述两图中的关系是一样的,因为它们具有同样的元组集合
对于关系的每个属性,都存在一个允许取值的集合,称为该属性的域(domain)。这样的话,如上图所示salary属性的域就是所有可能的工资值的集合,而name属性的域是所有可能的教师名字的集合
如果域中元素被看作是不可再分的单元,则域是原子的(atomic)。
例如,假设表上面有一个属性phone_number,他存放教师的一组电话号码,那么phone_number的域就不是原子的,因为其中的元素是一组电话号码,是可以被再分为单个电话号码的子成分。
假设phone_number属性存放来单个电话号码,但是如果我们把电话号码的属性值拆分成国家编号,地区编号,以及本地号码,那么我们还是把它作为非原子值来看待。如果把每个电话号码作为不可拆分的单元,那么phone_number属性才会有原子的域
空(null)值是一个特殊的值,表示值未知或不存在。如前所述,如果我们在关系instructor中包括属性phone_number,则可能某教师根本没有电话号码或者电话号码未提供。此时就可以使用null来强调该值不存在或未知
数据库模式
数据库模式(database schema):数据库的逻辑设计
数据库实例(database instance):给定时刻数据库中数据的一个快照
关系的概念对应于:变量
关系模式的概念对应于:类型定义
如同程序设计中,变量的值可能随时间变化,但是类型不变。类似的,当关系被更新的时候,关系实例的内容也随着时间发生了变化。相反,关系的模式是不常变化的。
如图所示的关系
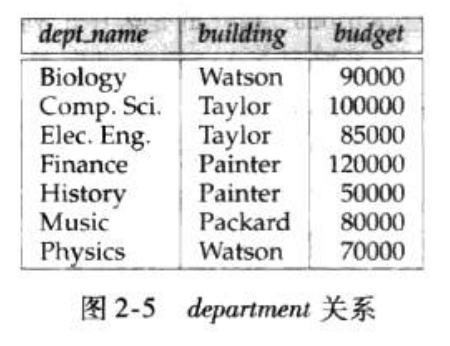
该关系的模式是:
depatment(dept_name,building,budget)
码
我们必须有一种方法能区分给定关系中的不同元组的方法。这用它们的属性来表示。也就是说,一个元组的属性值必须是能够唯一区分元组的。换句话说,一个关系中没有两个元组在所有属性上的取值都相同。(一组数据中如果有两组完全一样的就没意义了)
超码(superkey)是一个或多个属性的集合,这些属性的组合可以使我们在一个关系中唯一的标识一个元组。例如,一个关系中的id属性足以将不同的教师元组区分开来,因此id是一个超码。一个关系属性中可能也会有name,它不是一个超码,因为几个教师可能同名。 (你可以理解为这就像个身份证,QQ号。都是唯一的所以是超码,名字(昵称)可能重复所以不是超码)
超码中可能包含无关紧要的属性。例如,ID和name的组合是关系instructor的一个超码。如果K是一个超码,那么K的任意超集也是超码。我们通常只对这样的一些超码感兴趣,它们的任意真子集都不能成为超码。这样的最小超码称为候选码(candidate key)
几个不同的属性集都可以做候选码的情况是存在的。假设name和dept_name的组合,足以区分instructor关系的各个成员,那{id}和{name,dept_name}都是候选码。虽然属性id和name一起能区分instructor元组,但它们的组合id和name并不能成为候选码,因为单独的属性id已是候选码
用主码(primary key)来代表被数据库设计者选中的、主要用来在一个关系中区分不同元组的候选码
主码应该选择那些值从不或极少变化的属性。例如,一个的地址就不应该作为主码的一部分,因为它很可能变化
习惯上把一个关系模式的主码属性列在其他属性的前面,主码属性还加上了下划线
一个关系模式(如r1)可能在它的属性中包含另一个关系模式(如r2)的主码。这个属性在r1上称作参照r2的外码(foreign key)
关系r1也称为外码依赖的参照关系(referencing relation),r2叫做外码的被参照关系(referenced relation)
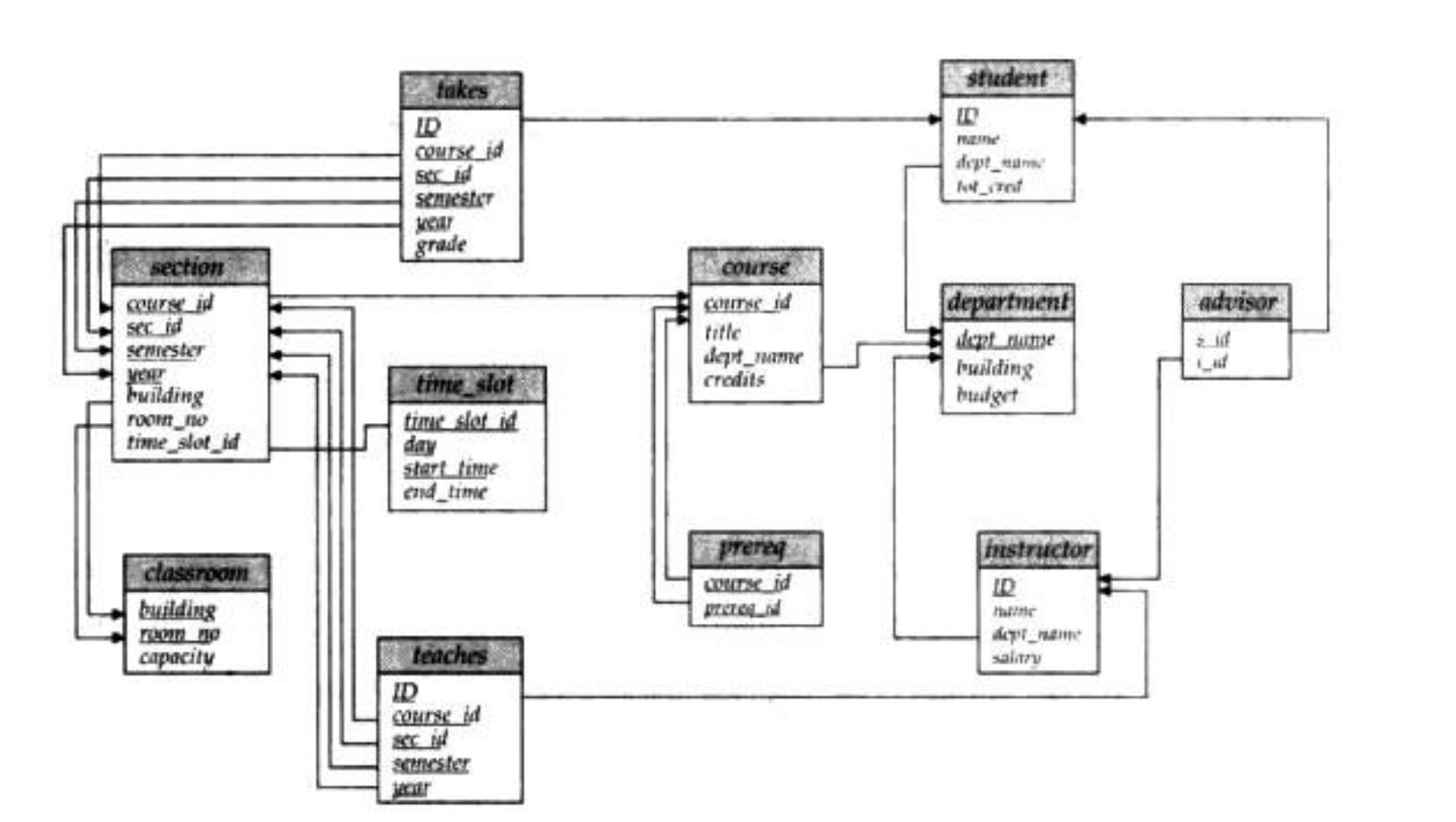
模式图
一个含有主码和外码依赖的数据库模式可以用模式图(schema diagram)来表示
下图展示来大学组织的模式图
- 每一个关系用一个矩形来表示,
- 关系的名字显示在矩形上方,
- 矩形内列出各属性,
- 主码属性用下划线标注,
- 外码依赖用从参照关系的外码属性到被参照关系的主码属性之间的箭头来表示
关系运算
过程化关系查询语言都提供了一组运算。
运算结果总是单个的关系,这个性质使得人们可以模块化的方式来组合几种这样的运算。
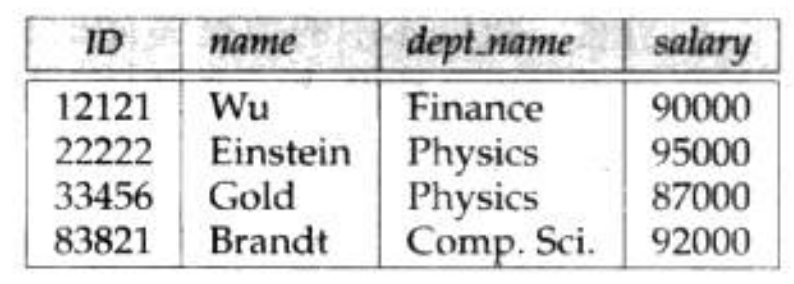
最常见的关系运算是从单个关系(如instructor)中选出满足一些特定谓词(如salary大于85000)的特殊元组。其结果是一个新关系,它是原始关系(instructor)的一个子集
例如我们从文章前面的关系中选择 salary大于85000的元组 得到的结果是
还有一种常用的运算,是从一个关系中选出特定的属性(列),
例如从文章前面的关系中列出教师的id和工资,但是不列出name和dept_name的值,那么其结果就只有id和salary两个属性。如图所示
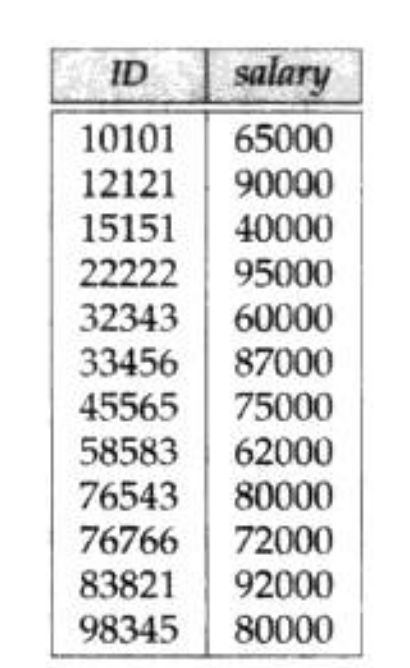
只具有被选中的属性
关系代数
关系代数定义了在关系上的一组运算,对应于作用在数字上的普通代数运算
关系代数运算通常以一个或两个关系作为输入,返回一个关系作为输出。
下面给出几个运算的概述,下一篇文章将会详细说明
